01
Dense counterfactual proxy
For each on-policy state, candidate trajectories are scored for efficiency, safety, and rule compliance, then converted into group-normalized advantages.
Counterfactual-to-Interactive Reinforcement Fine-Tuning for Driving Policies.
Overview
Open-loop supervised driving policies can look strong near expert states but fail once their own actions shift future observations. CRAFT closes this gap without changing the base architecture.
Method
The framework assigns distinct statistical roles to local counterfactual evaluation and real interaction, then regularizes adaptation toward reliable pre-trained behavior.
For each on-policy state, candidate trajectories are scored for efficiency, safety, and rule compliance, then converted into group-normalized advantages.
Executed rollouts supply event-driven rewards that correct proxy errors exposed by closed-loop interaction, using a value-free dual-clipped update.
An exponential moving-average teacher initialized from the pre-trained checkpoint keeps adaptation close to reliable behavior while allowing corrective shifts.
Visual Results
Select an algorithm and scenario to compare the same ego-view rollout before and after CRAFT. The two videos auto-play, wait for both videos to finish, then restart together.
Loading
Videos are stacked vertically. If one video is shorter, it waits at the end until both videos finish, then both restart from the beginning.
Empirical Picture
The paper reports consistent gains over the pre-trained policies on the full Bench2Drive closed-loop benchmark. The cards below summarize the main-table Driving Score and Success Rate improvements.
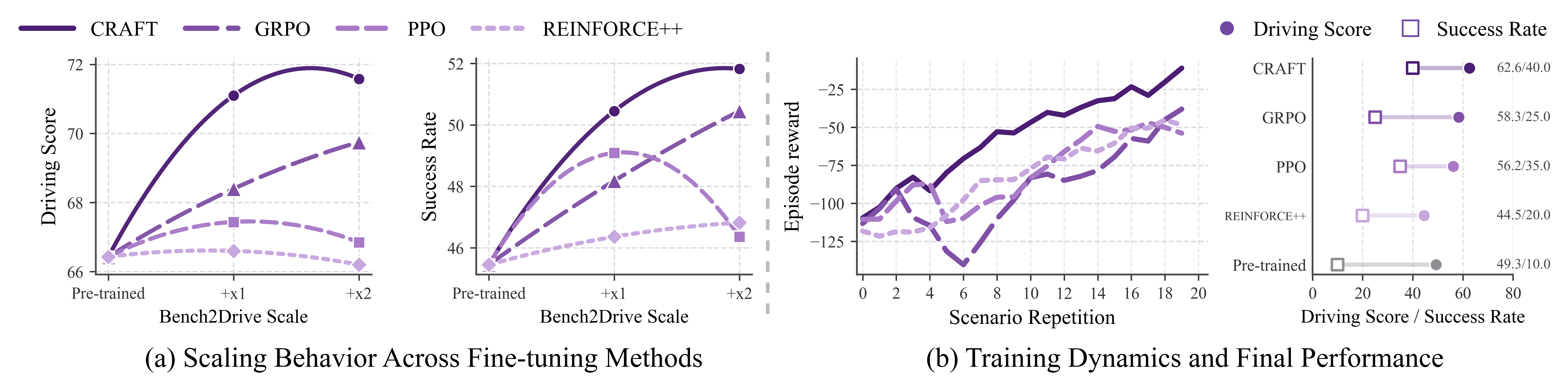
The counterfactual proxy provides broad optimization signal, while grounded residual feedback supplies the missing correction for interaction-dependent failures. Self-distillation stabilizes the shift around the pre-trained policy manifold.
Citation
Citation information will be updated when the public paper record is available.
@misc{chen2026craft,
title={CRAFT: Counterfactual-to-Interactive Reinforcement Fine-Tuning for Driving Policies},
author={Keyu Chen and Nanfei Ye and Yida Wang and Wenchao Sun and Danqi Zhao and Hao Cheng and Sifa Zheng},
year={2026},
eprint={2605.04470},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2605.04470},
}